
RAG just doesn’t cut it for structured data for AI

RAG (Retrieval Augmented Generation) has become the de facto design pattern for AI applications.
To be fair, it’s a great way to give LLMs the context they need to generate more tailored responses, especially when the data is unstructured, such as text, images, videos, etc. Organizations today have RAG pipelines in place to make their mostly-static data work with LLMs. However, practically speaking, when it comes to correctness, accuracy and freshness of data, RAG just doesn’t cut it for most operational business use cases.
The limitations of RAG
RAG uses a vector store to aggregate, summarize and tokenize the data used to provide the context for LLM prompts. Vector stores use fuzzy matching (i.e. nearest neighbor searches) to retrieve the needed data, which works well for unstructured data. However, vector stores were never designed to do point lookups or exact data retrieval, which means data accuracy will always be questionable.
Even when the combination of RAG and LLM meets the bare minimum for production, the configuration won’t be useful for business-critical workflows. For example, if you need to check for criminal records on “Joanna Smith” during your hiring process, the system might confuse “Joanna Smith” with “Joan Smith” yielding a false result.
Also, because data is extracted from its original source, transformed and aggregated through data pipeline(s) into the vector store, it is, by definition, stale. This lack of freshness makes using RAG for real-time decision making use cases a challenge. As a result, the RAG approach becomes useless for many business-critical workflows.
A simple customer support example
Let’s talk through these challenges through a simple example. A customer makes an online purchase, but the system glitches and doesn’t provide an order number, leaving the customer wondering whether the order was received and what its status is. A customer support chatbot (which is almost always the first line of support offered by ecommerce sites) using RAG for data retrieval won’t have immediate information about the order status — the event just happened, and the order number wasn’t ETL’d into the vector store yet. So from the chatbot’s perspective, the order number is unknown. In this case, AI fails to help, and the client is transferred to a human support agent. The human checks the order management system and provides the order status. In this case, the data existed but could not be effectively accessed by the automation. So a human needed to be involved, wasting their precious time and delaying the customer’s resolution.
If the AI agent was directly connected to operational data sources, it could fetch the right data from the right sources — whether a database, data warehouse, or API — and use to help the customer in real-time. Current data pipelines and consolidation-based systems are just not suited for these types of ad hoc use cases.
Its time for a new data infrastructure, tailored to GenAI
For AI to move forward, it must integrate seamlessly with business-critical systems. That means:
Directly and natively querying databases, data warehouses, and API-based systems in real time.
Eliminating reliance on pre-defined, brittle and rigid ETL workflows for AI-driven decision-making.
This is how data infrastructure for AI should be. This is what we are building at Snow Leopard.
I’ve seen the limitations of data consolidation approaches first hand from building cloud and data infrastructure for decades. Hence, at Snow Leopard, we believe in an intelligent, federated approach to data instead.
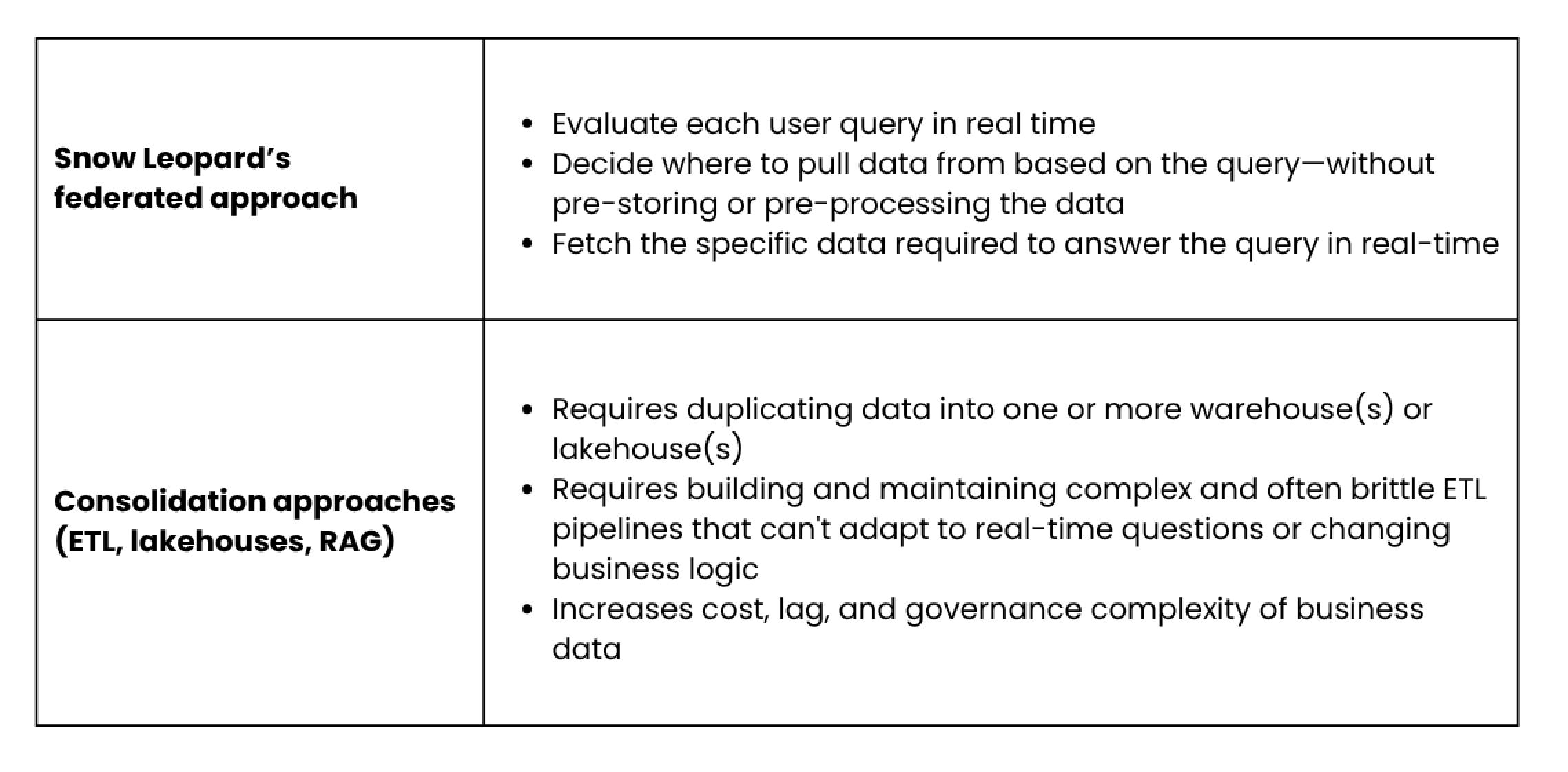
We are making it simpler and easier for AI developers to use their operational business data for AI applications in production and on-demand, without the need for complex data workflows and pipelines.
Subscribe to our blog to follow our journey as we share our learnings!
