
Snow Leopard vs. Frontier Models – Do Semantic Layers Still Matter
Spoiler alert: they do! In head-to-head comparisons, Snow Leopard was consistently 95+% accurate, dramatically outperforming current frontier models (Opus 4.7 and GPT -5.5)

Frontier AI models have improved dramatically over the last 12 months. LLMs like GPT-5.5 and Opus 4.7 are capable of sophisticated reasoning, code generation, summarization, and information synthesis, often producing remarkably capable results when given enough context.
Naturally, this raises an important question for enterprise AI systems – do we still need semantic layers over structured enterprise data, or can we simply connect frontier models directly to enterprise systems and let them figure everything out?
We ran this benchmark to answer exactly that, and the results reinforced something we have believed for a long time: enterprise data access is not just a reasoning problem — it is a semantic systems problem, and the semantic layer still matters.
It’s more than a Text2SQL problem
There is a tendency in the industry to frame structured data retrieval as a text-to-SQL problem. Can the model generate valid SQL? Can it construct joins correctly? Can it navigate relational schemas?
Those capabilities matter and they are table stakes.
The harder problem is accuracy and correctness. A query can execute successfully and still answer the wrong question or fetch the wrong data.
This distinction matters enormously for agents. Agents cannot perform meaningful enterprise work without interacting reliably with systems of record. A workflow automation agent making decisions from subtly incorrect data becomes operationally dangerous very quickly.
This benchmark was designed to evaluate whether frontier models alone can perform structured enterprise data retrieval tasks accurately and consistently under realistic conditions.
Benchmark Setup
We evaluated three systems:
GPT-5.5
Opus 4.7
Snow Leopard
Dataset
For the benchmark, we used the public BigQuery baseball dataset.
We chose it because it contains realistic relational structure, multiple interconnected tables, and enough complexity to expose semantic retrieval failures without requiring proprietary data.
Evaluation Methodology
The benchmark was intentionally designed to create as close to an apples-to-apples comparison as possible. All systems used the same dataset, the same underlying BigQuery connection, and the same evaluation harness. No schema manipulation, manual ontology generation, or prompt tuning was applied specifically for the benchmark.
We used a frontier model to generate 100 questions along with expected answers based on the full dataset schema. We also have a grader as part of the harness to evaluate whether the returned answer logically and intent-matched the expected answer.
For Snow Leopard, we connected the dataset and used Snow Leopard’s /retrieve API to answer the benchmark questions. Note that Snow Leopard does the semantic layer generation automatically during initial connection to the dataset, so no further setup or prompting is required besides calling the API.
For the frontier model baseline, we provided the full dataset schema, the natural language question, and basic instructions to generate BigQuery SQL.
Snow Leopard is not just a Text-to-SQL system. It performs end-to-end structured data retrieval from the required databases. To keep the comparison equivalent, the LLM-generated SQL was executed against BigQuery and the resulting data was retrieved as part of the evaluation, rather than evaluating query generation in isolation.
Evaluation Criteria
This is not just a Text-to-SQL benchmark – generating syntactically valid SQL is not particularly difficult for frontier models. What matters in production environments is whether the system retrieves correct information consistently and reliably.
We evaluated:
correctness of final answers
consistency across runs
retrieval accuracy
end-to-end reliability
We ran the benchmark three times across all systems and classified results into four categories:
Correct — the system returned the expected answer for all 3 runs
Nondeterministic — for the same question, the system answered correctly at least once, but not all 3 runs
Incorrect — the system returned an incorrect answer for all 3 runs
Failed — the system failed to produce a result because it generated invalid SQL all 3 runs
Results
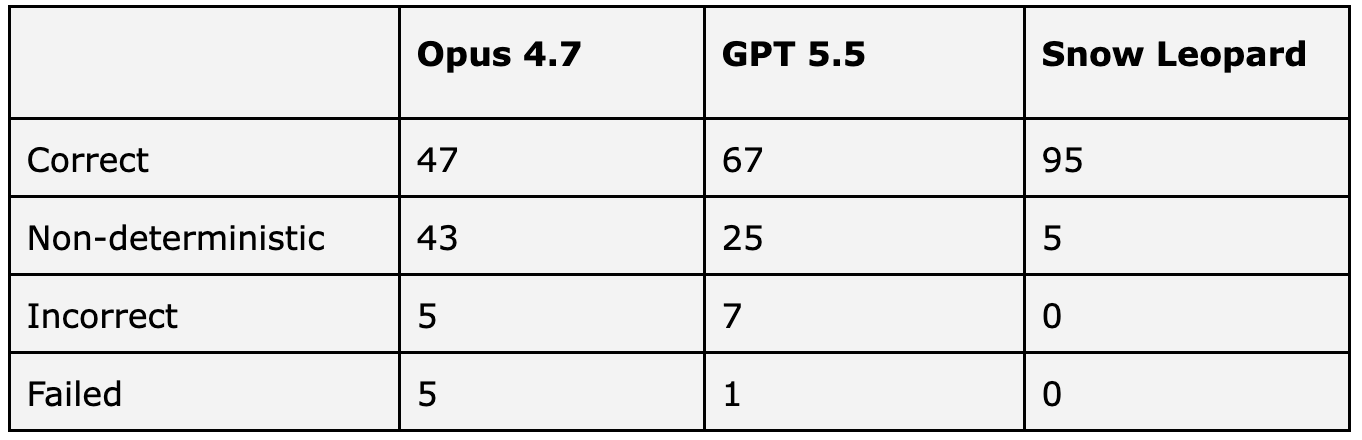
100 questions, 3 runs. Snow Leopard was consistently 95+% accurate
Semantics Still Matter
The benchmark reinforces an issue enterprise teams are currently grappling with: raw frontier intelligence is not sufficient for enterprise agents to automate critical workflows.
Enterprise environments contain implicit meaning and terminology that schemas alone do not represent well. Data and schema drifts are inevitable and not always captured in stale catalogs. Business logic evolves continuously. Data relationships emerge organically over years of operational complexity.
This is precisely why semantic knowledge matters.
For agents to do work truly autonomously, contextual-data-correctness is critically important. The downstream cost of data-related mistakes compounds quickly. A slightly incorrect or non-deterministic data retrieval feeding an autonomous workflow is a huge operational problem.
Why Snow Leopard is just Better
The current semantic-layer systems in the market make semantics building entirely the developer’s problem. Developers are expected to define ontologies, encode business logic and business metrics, tune retrieval behavior, and build evaluation systems, iterating endlessly before they can even begin building the actual agent. And, they are expected to do this for every single database or data source they need to use for that agent.
Snow Leopard takes the opposite approach.
Instead of asking developers to manually construct semantic infrastructure, Snow Leopard builds semantic intelligence automatically, as soon as a data source is connected.
Snow Leopard is optimized around the full data retrieval operation:
Semantic understanding
Entity and naming conflict resolution
Dialect and dataset related grounding
Retrieval reliability
That produces significantly more consistent and accurate end-to-end behavior under realistic conditions without manual intervention.
Connect your PostgreSQL, BigQuery, or other database, and Snow Leopard immediately creates structured semantic understanding around the data leading to high accuracy out of the box, for all the datasets, so developers can start building reliable enterprise agents in minutes — not weeks or months.
That is ultimately the difference.
The semantic layer still matters. We just don’t think developers should have to build it all themselves.
Future Work
We know that the nondeterministic behavior is primarily from the more complex queries. Making these types of queries consistently accurate requires human intervention via additional context. To achieve that, we are working on an automated feedback system. Stay tuned!
Subscribe to our blog to follow our journey as we share our learnings!
