
Structured data for AI: Snow Leopard vs. MCP
Snow Leopard, with its semantic data intelligence, significantly outperforms LLM+MCP (95% accuracy vs. 74%, for real-world datasets)

Working with structured data for AI is still much harder than it should be. At Snow Leopard, we believe the deeper issue goes beyond tooling and infra. At its core, it’s a problem of semantics.

Anyone who’s tried to get reliable answers from operational data in AI systems knows the pain—data is often stale or inaccurate, and building and maintaining data pipelines is a constant uphill battle.
In a previous post, I laid out what's missing today: a reliable way to get AI systems to query structured data accurately and consistently. We’ve found that the biggest gap is the semantic layer—the business logic required to understand which data to query, when, and how. Without that, even the most advanced models struggle to answer even moderately complex questions.
This semantic understanding is usually locked in the minds of the people who originally built the pipelines and structured the databases. Extracting that knowledge is tough. Using it in real time for AI-driven data access is even tougher.
That’s why at Snow Leopard, we’re building a system to extract, encode, and use this semantic knowledge for real-time, intelligent data retrieval.
We know our solution is promising. Given the rapid evolution of reasoning models, we wanted to benchmark our system vs. today’s state-of-the-art data retrieval tooling to get a current baseline.
Evaluation setup
We ran two core experiments: one with a synthetic Postgres database and one with a real-world dataset in BigQuery.
Our goal for these experiments was to establish a baseline of how Snow Leopard measures up with respect to accuracy and consistency, without compromising data privacy. The latter isn’t as straightforward with LLM-based retrieval agents as you might imagine. More on that later.
This post walks through our benchmarking process, our learnings, and what we think the findings mean for the future of enterprise data + AI.
Current state of the art: Intelligent LLMs +MCP
We used the Model Context Protocol (MCP) in combination with reasoning LLMs as our “state of the art” baseline. This has become a common setup in the developer community, especially for querying relational databases with natural language.
Setup 1: Synthetic Postgres database
We created a simple Shopify-style Postgres database with a manually-built schema. Data was initially generated using an AI-based data-generation tool, then refined manually to better reflect a realistic dataset. The aim here was to have a basic dataset as a baseline for our experiments.
Tables: 4
Dataset size: 128KB
We compared three configurations:
Snow Leopard (schema-only, single-shot, privacy-preserving)
Snow Leopard uses schema-only with a single-shot query to an LLM to generate queries in real-time for retrieval.
It doesn’t explore the data ever, making it a data-privacy-preserving solution.
MCP + Claude (full tool calling enabled)
We used the Claude API with Sonnet 3.7 (Anthropic’s latest reasoning model at the time) with an open-source Postgres MCP Server we found here.
For this experiment setup, full tool calling was enabled, which means Claude could explore the data as it saw fit to generate each SQL query.
MCP + Claude (schema-only, single-shot)
Same setup as above–Sonnet 3.7 with open-source Postgres MCP Server
For this variation, full tool calling was disabled, so Claude had to generate the SQL query in a single shot based on the schema it had access to through the MCP server.
Setup 2: Real-world BigQuery dataset
For the second set of experiments, we worked with a real dataset from one of our design partners (in the Fintech-SaaS space). This was a production BigQuery dataset, with rich, messy real-world semantics and a more complex schema.
Tables: 50K+
Dataset size: 80GB+
Again, we compared three configurations:
Snow Leopard (schema-only, single-shot, privacy-preserving)
Same as above.
MCP + OpenAI 4o (tool-calling enabled)
NOTE: For this experiment variation with full tool calling was enabled, we used OpenAI’s 4o-mini model because our partner required an OpenAI-based solution for data privacy reasons.
MCP + Claude (schema-only, single-shot)
Same as above.
Evaluation methodology
Primary metric: Accuracy, measured as correct answers to a fixed set of questions.
Scoring: All questions were manually graded to create a "golden dataset" for each case.
Modes tested:
Tool-calling enabled (multi-shot, with data exploration)
Tool-calling disabled (single-shot SQL generation using only schema)
This last distinction was especially important to us.
At Snow Leopard, we care deeply about data privacy.
With decades of experience building enterprise-grade databases and data storage solutions, our team understands the critical importance of handling operational enterprise data with care, and respecting data governance and privacy requirements.
Snow Leopard is built from the ground up to generate queries in a single shot without ever exposing the data directly to an LLM. Snow Leopard is simply a pass-through for an AI agent or AI application, generating SQL queries based on schema-alone for real-time data retrieval.
So if we were going to compare Snow Leopard with existing setups fairly, we had to test both tool-calling (multi-shot) and schema-only (single-shot) approaches.
Aside: Building our own BigQuery MCP server
When we started this experimentation cycle, after much searching we found, to our surprise, that there was no official BigQuery MCP server from Google.
The community implementations we found seemed experimental and buggy (we contributed patches upstream to one of them). Schema calls were made via tool endpoint calls, not resource endpoint calls. In addition, there was no way to restrict query calling in a way that respected our privacy model.
So we built our own BigQuery MCP server. You can find the repo here.
Results
Postgres dataset – 29 questions
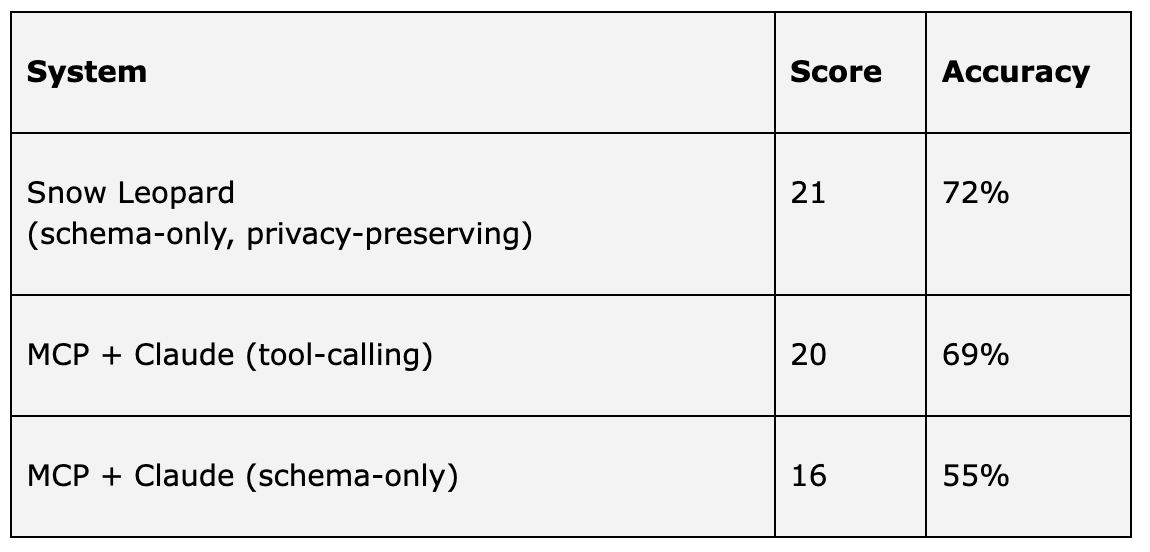
BigQuery dataset – 39 questions

What we learned
Setting up MCP with Claude or OpenAI was relatively easy. Building a clean MCP server that implements the spec well was also very doable.
It is notable that while there are a lot of discussions around MCP and using MCP servers to explore data sources, MCP servers are not yet ubiquitous for all data sources, especially structured ones. That means you should expect to build your own if you want to do any realistic MCP-based experimentation with your data sources.
Overall, we are enthusiastic about MCP and believe MCP’s evolution will help accelerate Snow Leopard's adoption because it will allow us to manage data retrieval and orchestrate queries without writing and maintaining separate connectors for each data source.
Considerations
Performance and token utilization
Tool-calling setups typically use a multi-shot approach, where the LLM agent explores the dataset before generating a final SQL query. This back-and-forth interaction with the data introduces two key trade-offs:
Performance Overhead – Multi-shot workflows incur additional latency compared to single-shot query generation.
Higher Token Consumption – Each exploratory step uses more tokens, potentially increasing cost.
These aren't necessarily deal breakers, but they’re worth keeping in mind if you're building similar systems. Multi-shot interactions may not scale efficiently.
Data privacy
The default behavior for tool-calling agents is to query the database and explore your data on every request, as mentioned above. This implies that LLM agents use MCP servers to retrieve live data from your database multiple times during a single request. So if you’re using a vendor-hosted LLM (like Claude or o3), you may be unknowingly sending your internal data to that vendor, query by query. This includes tools like Claude desktop.
While this behavior is implicit, it can become a serious concern if data privacy is critical to your organization.
For many environments this is a deal-breaker and one of the main reasons we built our own MCP Server for BigQuery; we specifically wanted to restrict tool-calling behaviors and protect our design partner’s data.
Snow Leopard was explicitly designed to never explore the data. It uses only the schema to generate queries, and you can BYO LLM for the final response—ensuring full control over what goes in and out.
Semantic understanding is the missing piece
LLMs are powerful but they don't have any inherent semantic information about a given dataset.
Most real-world operational data are filled with implicit logic, domain-specific naming conventions, and contextual rules. Out of the box, even the most intelligent models won’t know, for example, that a column named purch_dt actually refers to a purchase date in an ecommerce database.
When running the LLM+MCP setup on our design partner’s use case, we saw this clearly. We had to explicitly give the LLM the exact table names for it to generate SQL queries that worked, since the business logic is embedded in the table names. Otherwise, the models got lost. When we let the LLM fetch all available tables in the dataset, it blew out the context window.
Even in this relatively small relational schema, without semantic guidance, the system simply didn’t know how to navigate the data effectively.
Our takeaways
Our experiments confirmed that:
Semantic information makes a measurable difference in the accuracy, consistency, and quality of results. Snow Leopard’s focus on semantics leads to significantly better performance on real-world datasets.
Even with constraints (smaller cheaper models, single-shot, schema-only), Snow Leopard is:
Significantly better than state-of-the-art tools for real, production-grade, complex datasets.
On par with state-of-the-art tools when dealing with simple databases.
This gives us confidence that we’re building in the right direction. Our bet on building a semantic layer, and designing towards intelligent understanding of the data, is the right one. And while there's more to grow, optimize, and scale—these early signals validate our core approach.
We’re focused on solving a real, hard problem that’s blocking structured data from being useful for AI, and doing it in a way that respects privacy and reliability.
If you’re building similar systems or struggling to use structured data in your AI agents and applications, we’d love to hear from you.
Subscribe to our blog to follow our journey as we share our learnings!
